
10 catalogs, 3 ETLs, 2 Postgres and a partridge in a pear tree
A very acquisitive year

Are you familiar with geomorphology? It’s a field within geology, the study of how landscapes evolve. It occurred to me this morning that this newsletter has been a bit of geomorphology of the changing data landscape this year, a modern data stack (MDS) morphology, if you will.
The problem with geomorphology is that you rarely get to see change happen; you can see the current state and infer from signals in that state the processes that took thousands or millions of years to create it.
We had no such challenge in MDS morphology in 2025. A LOT of stuff happened…
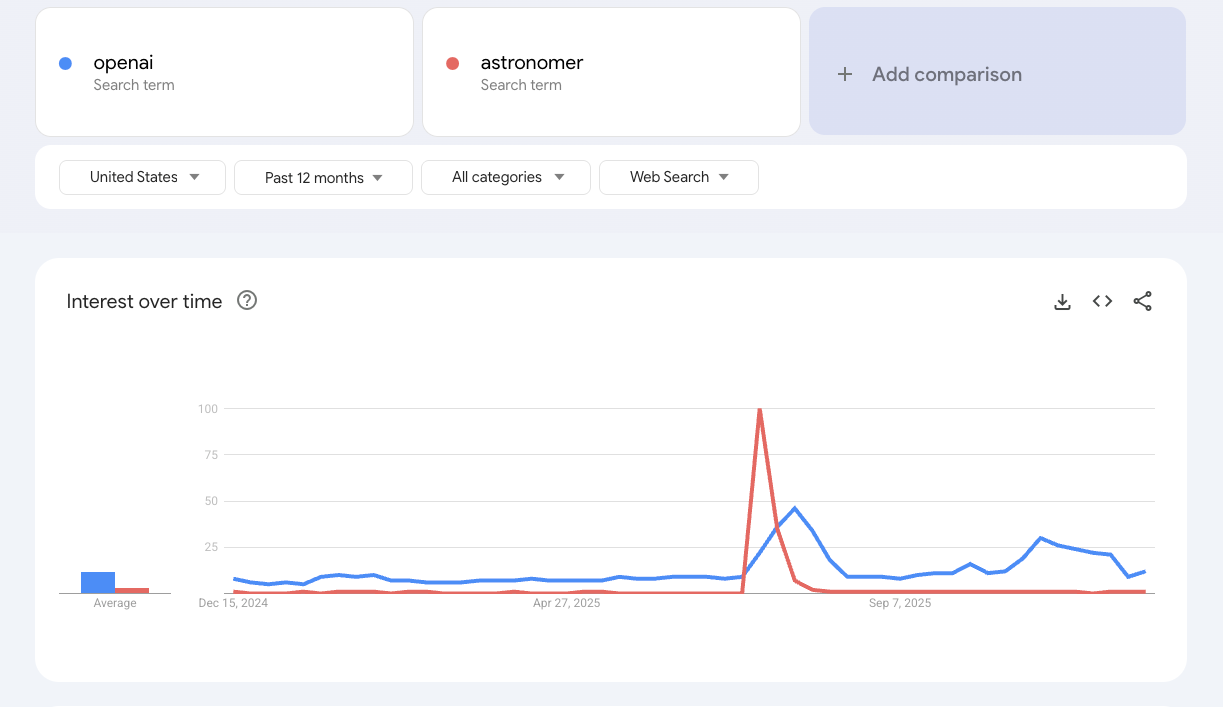
AI continued drive headline numbers for funding ($200B+), acquisitions, news headlines/controversy (though for a heady 2 weeks in July, MDS staple Astromer took the crown)...
In data, there were So. Many. Acquisitions. Thus the title of this post, lots of activity in the catalogue/metadata/semantic layer/ontology space (as I wrote about earlier this year). A bit of ETL. Some Postgres (wrote about that too).
The biggest news came in the past 6 months.
I started this newsletter writing about Fivetran and dbt, so perhaps it’s fitting that they announced they are merging. A not-too-surprising development that has dbt devotees worried about the future of the well-loved open source project and community.
Confluent is being acquired by IBM for $11B, an earthquake for the streaming world as the leading commercial and open source projects will be subsumed into tech’s looming dinosaur, causing yet more questions and consternation about the future of another critical open source project, Kafka.
Databricks and Snowflake both bought a Postgres…
From a Streamkap product and company perspective, we’ve also had a huge year, record growth, launching on the Snowflake Marketplace (for private offers for now), Streaming Transformations in product, and helping customers with CDC from hundreds of thousands of tables into Snowflake.
We’ll dig into that and more below in the MDS morphology section. But first…
Streamkap Customer Story - InHire
Rockset was one of our early partners in the Streamkap journey. We helped customers load data into the real-time database. Cut to June 2024, Rockset announced that they were being acquired by OpenAI (hey, yet another acquisition!) and that the service would be completely shut down. Customers on month-to-month plans had just 3 months to migrate🫠.
That takes us to a fateful Saturday in August, Juliano Tebinka, Co-Founder and Chief Data Officer of InHire, a leading AI applicant tracking system in Brazil, was looking for solutions to replace Rockset. InHire had built key real-time customer-facing functionality, AI agents, reporting, applicant workflows, and more around the native integration between their production database, DynamoDB, and Rockset. Both this integration and Rockset itself would cease to be available in just a few short weeks. As Juliano recently put it to me in a LinkedIn comment:
“You nailed the story, but left out the part where I almost had a full-on meltdown when that shutdown email hit 😂”
Juliano was working on a Saturday, trying to find a solution as the clock ticked down. He had looked at options like Fivetran, Airbyte, Confluent, and others but they either couldn’t deliver. Either failing to meet real-time requirements, were too rigid, too expensive, or too slow to engage with.
Juliano found Streamkap via a Google search, and when he landed on the site he jumped into the chat to ask about his specific use case:
“I sent a chat message on a Saturday evening, not expecting a reply,” Juliano recalls. “Someone responded almost immediately. That was instrumental. We realized we would get the support we needed.”
It turned out we were well set up to help Juliano build a replacement.
The plan was to replace Rockset with ClickHouse, but while Rockset’s native integration with DynamoDB and document-based structure worked seamlessly with InHire’s data structure, ClickHouse did not. The data would need to be cleaned up and structured in-flight and in real-time before loading into ClickHouse.
Luckily, Streamkap was perfect for the job. Our Flink-powered stream processing handled the transformations to get the data in the right shape while maintaining sub-second latency. Best yet, we were able to deliver in just 3 weeks with no dedicated resources on the InHire side. Again, in Juliano’s words:
“3 weeks. THREE. We ripped everything over to Streamkap and now we’re faster, more reliable, and I still don’t have to pretend I’m a data engineer haha.
Shoutout to you for actually answering the website chat on a Saturday night and turning this from “oh sh*t” into “we got this.” Streamkap isn’t a vendor – you’re the crew we call when the house is on fire, and somehow everything still ships on time.”
Since that initial deployment we’ve helped Juliano and team expand their use cases and are now replicating to both ClickHouse and Databricks for their fast and slow workloads respectively. Check out the full InHire + Streamkap case study on the website.

Streamkap Product Update
It’s been a big year for us on the product front; some highlights below.
1. Flink Stream Processing (”Shift Left”)
Tools to clean, mask, and transform data before it reaches the destination.
Multi-Language Transforms: Support for writing lightweight snippets in JavaScript and Python.
TypeScript Development Kit (TDK): A local workflow for building, testing, and bundling TypeScript transforms with npm dependencies.
2. Expanded Connectors and Kafka Access
New Destinations: Iceberg is hot, we now power real-time streams to Apache Iceberg, we also released native connectivity for Motherduck and DuckDB
New Sources: Real-time change data capture for PlanetScale and Supabase.
Direct Kafka Access: New visibility and management tools for Consumer Groups & Schema Registry.
3. Snapshot Improvements
Filtered Snapshots: Allows for partial snapshots to capture specific data rather than whole tables! Filtered Snapshots.
Snapshot Progress: Real-time visibility into progress and ETA for active snapshots.
MDS Morphology 2025
$20B+ dollars of data landscape acquisitions were announced this year, the biggest, Confluent, at $11B, capping off the year earlier this month.
I will focus a bit more on that in the future. Let’s look at the Fivetran/dbt merger first.
I’ll start by saying, I get it. From both a dbt perspective and a Fivetran perspective, this was very rational.
As I wrote previously, dbt has scrapped their way to within striking distance of meeting their $4.2B valuation from 2021. What I didn’t cover in that post was how they could actually get liquidity at that valuation.
The IPO market these days is closed to companies below $500M ARR, a milestone likely 2-3 years away, at minimum. dbt has 2 obvious acquirers, Snowflake and Databricks, and I’m sure both have thought long and hard about an acquisition but clearly neither felt compelled to pull the trigger. My sense is that they are already getting the milk, why buy the cow, dbt is perennially a top partner in terms of credit consumption for Snowflake, and I presume Databricks, what advantage would buying dbt confer? Mostly a competitive one, e.g. if Databricks bought dbt, they could use it to build a migration path from Snowflake to Databricks and/or stop supporting Snowflake. Clearly neither Snowflake nor Databricks felt this was compelling enough to offer an acquisition more compelling than a Fivetran merger…
Speaking of, with a Fivetran merger, the combined ARR of both companies is $600M. That’s good enough to go public today ✅. With closing the merger and the actual IPO process, we’re probably talking mid to late 2026 for the IPO but a ~1 year very clear path to liquidity is a lot more attractive than years of fighting to maybe get there in 2028/2029,and probably having to raise money again in the meantime.
All of this was the carrot for dbt. Fivetran also had a stick. They acquired Tobiko Data, the creators of SQLMesh (dbt’s strongest open source competitor). I’m sure part of the conversation was, “that’s a nice transformation business you have there, it would be a shame if something happened to it”

What about Fivetran? Well, I suspect they were already going to go public in 2026. But they were under different pressure. Their biggest partner, Snowflake, announced a native solution for ETL this year, Openflow. While Openflow is not much of a threat in the short term, it doesn’t offer the ease, simplicity, and polish that Fivetran (and Streamkap) offers out of the box today, if you’re a public market investor looking at the long term strategic implications. That is going to be a big question.
The combination? Fivetran and dbt are marketing it as the open data stack. Part of this was, I’m sure, focused on using the word “open” strategically, to ease concerns about the implications for the dbt open source product and community under the boot of Fivetran’s very, ehem, commercial approach to customer relationships. But another part was positioning against the increasingly all-in-one solutions offered by Databricks, Snowflake, and MSFT Fabric. The giants are pitching a one-stop shop, whether or not they deliver on that promise is a different question…
So, enter dbtran or fivebt or fishtran, the savior of the modern data stack. The OPEN data stack. They will provide all of the everything, EXCEPT the compute. That part will be your choice, giving you freedom and flexibility. I think this positioning is fine, make sense, buuuut if you look at the diagram from the announcement below. What is the first thing you think?

For me? I think, boy it seems likely they are going to find a compute later to slot in there in the next couple of years…
Fivetran has been making some noise around iceberg for a while so it could be something like Dremio or Starburst, the startups that were early to the iceberg compute play. Motherduck also comes to mind, built on the back of MDS darling duckDB.
Speculation on the compute layer aside, what does this merger mean for beloved dbt? The message in the announcement, from George Fraser, Fivetran CEO, was that the open source project would remain a key focus, as would the community. In fact, that he would be a fool to disrupt either. I believe that was a truthful statement. However, what is the main reason that mergers and acquisitions fail? Culture fit, or lack thereof. dbt and Fivetran are unquestionably different cultures, which will dominate?
On top of that, with the IPO coming, a quote from Mike Tyson comes to mind, “everybody has a plan until they get punched in the mouth”...
2026 will be interesting! I’m excited:)
The geomorphology analogy is spot on. The Fivetran/dbt merger positioning as the "open data stack" is clever marketing, but the empty compute slot in that diagram is basically a neon sign saying "future acquisition here." The culture fit question between dbt's community-first ethos and Fivetran's commercial approach is gonna be the real test. I've worked with both tools and the difference in how they engage with users is night and day. The SQLMesh acqusition was definitley the stick in those negotiations, nothing says "lets merge" like a competitor quietly building momentum in your backyard. One thing though, the path to $600M ARR for IPO viability assumes the integration goes smoothly, which is a big if considering how many post-merger integrations fail even with good cultural alignment.
Confluent at IBM makes sense when you consider all the other enterprise open source in their portfolio. eg Redhat, Datastax (Cassandra), Ahana (Presto) I wouldn’t expect anything like a license rug pull