


With Snowflake Summit coming up, what better time to look at Snowflake’s place in the streaming landscape.
But wait, you say, Snowflake is a batch data warehouse.
What does it have to do with Streaming?
The rumoured acquisition of RedPanda seems to have fizzled so what gives?
I wrote previously about how streaming would become the dominant data processing approach, vs batch, with a combination of it getting easier, cost-competitive, and more market forces pushing towards real-time. All of which are happening.
How does Snowflake fit in? Well, to start, they are one of the most popular data warehouses (erm, excuse me, Data and AI Clouds), this means that if Snowflake makes streaming easier, it impacts a huge number of existing data teams who are already Snowflake customers.
When we started Streamkap in 2022, your best option for streaming data to Snowflake was Snowpipe. Launched in 2018, Snowpipe continuously loads data into Snowflake by automatically detecting new files in cloud storage and using predefined COPY commands to ingest them in near real-time.
This worked fine, and still does for files in particular, but for event data or database change data capture, it was more complicated and expensive than other options. This meant it was reserved for cases where you really needed to use it. It was also only good for latency in minutes.
In late 2022, a new feature went into Private Preview, Snowpipe Streaming. Streamkap started testing very early on and working with the product team developing Snowpipe Streaming, led by Xin Huang.
This was a game changer (though I wish they had come up with a more unique name, it’s easy to confuse with Snowpipe even if you write out the full name every time). Snowpipe Streaming introduced true streaming, there was no staging in S3 and batching in, effectively a Kafka consumer inside Snowflake that streams messages directly into Snowflake as a serverless process that does not require a warehouse.
This meant, for raw data, end-to-end latency of a few seconds from the source database, through Streamkap, into Snowflake. The only caveat was that it’s append-only, we’ll come back to that in a bit.

Credit Upsolver
So Snowpipe Streaming is fast, what about costs? Well, I’ve got good news for you there as well. Compared to Snowpipe, it’s up to 92% cheaper. Compared to batch loading processes, it depends on frequency, but with an ETL tool like Fivetran which uses COPY INTO, we’ve seen Snowpipe Streaming be 100x cheaper. There are some dependencies but generally, it works out to around $30 per Terabyte!

This is the kind of shift that has data teams looking at streaming in a new light. In terms of Snowflake credit consumption, it's less expensive to have your data available in Snowflake in seconds via streaming than every 15 minutes with a batch ETL tool. Add savings on the ETL tool as well, and you’re really cooking.
I did mention a caveat above, Snowpipe Streaming is append only. That means that if you’re doing CDC on a database and getting update events, you’ll need to do some processing on that raw table to create the current state view of the source. That’s where the next innovation comes in… Dynamic Tables.
Dynamic Tables came out a few months after Snowpipe Streaming as a wonderful complement to streaming ingestion. Dynamic Tables automatically refresh and materialize the results of SQL queries into a target table. The magic is that you simply set a target latency, currently as fast as 1 min*, and Snowflake figures out the most efficient path to get there. Dynamic Tables simplify data pipeline logic by letting you define transformations as SELECT statements, with Snowflake handling dependencies, freshness, and incremental updates.
If you combine Snowpipe Streaming and Dynamic Tables, the impact on latency and cost is huge.
Our customer, SpotOn, switched from batch ETL data loading and incremental debt modeling to Snowpipe Streaming and Dynamic Tables to achieve 4x faster end-to-end latency AND 3x lower total cost of ownership.
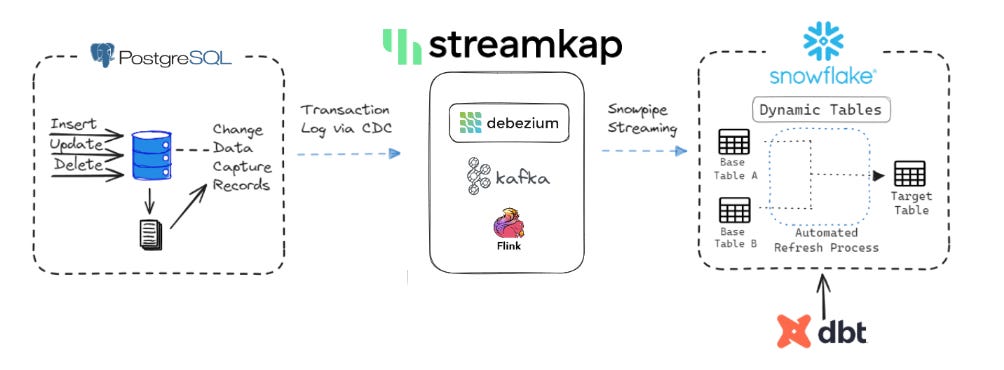
Step-by-step guide:
Ingestion: A PostgreSQL database generates Change Data Capture (CDC) records from its transaction log. Streamkap captures these changes and then uses Snowpipe Streaming to send these CDC records directly into Snowflake, populating staging tables.
Transformation: Snowflake Dynamic Tables are then defined with SQL queries that read from the staging tables (which are continuously updated by Snowpipe Streaming). These Dynamic Tables perform transformations—which can include joins between the staging tables, aggregations, or filtering—to derive a Target Table. (A more effective approach, however, is often to perform as many transformations as possible earlier in the pipeline, for instance, using Streamkap hehe, leaving only necessary transformations for this stage.)
Automatic Refresh: Snowflake automatically detects new data in the staging tables and triggers an incremental refresh of the dependent Dynamic Tables based on their defined target lag.
If you’d like to learn more about this, we did a webinar with Marcin Migda from SpotOn and have written a summary case study of their results.
Who's headed to SF for Snowflake Summit! I'll be there and keen to meet with folks to talk data, ETL, and Streaming. DM me on LinkedIn or book a meeting here.
Warmly,
Paul Dudley