
We put the Streamkap in Kappa Architecture
🤔 How Kappa Architecture Supports Real-Time Processing.

Hi Folks,
Inquiring readers may be wondering where the name Streamkap comes from.
Well, I hope the stream part is self-explanatory, but what about kap?
It’s short for Kappa. As in Kappa architecture, we believe it is the center of the shift-left movement we talked about last week, on which there was more related news from Confluent and Databricks this week.

Anyway, back to Kappa architecture. Let’s start with a bit of history.
Before Kappa architecture, there was Lambda architecture. Lamba architecture separates batch and stream processing into different layers. The problem? Maintaining separate code bases for batch and streaming and the associated complexity, cost, and ultimately inferior performance.
When we started Streamkap, these challenges were exactly what we set out to solve for, not introduce, to organizations.
Enter Kappa architecture
Kappa Architecture emphasizes simplicity and efficiency using a unified stream processing approach. It processes events incrementally, eliminating the need for a separate batch layer.
This architecture is particularly suitable for use cases that demand:
Frequent updates to data
Low-latency processing
Real-time insights
A simpler architecture compared to dual-layered designs
Kappa Architecture treats all incoming data as a stream, offering a more flexible and scalable solution. While the focus is on streaming, Kappa Architecture can still accommodate batch outputs as processed streams are written to storage systems. This capability ensures flexibility in how data can be consumed, and addresses use cases that may require either batch or real-time outputs.
Although it has existed for several years, Kappa architecture is becoming increasingly popular as customer-facing, operational, and AI workloads increase demand for real-time data.
Understanding Kappa Architecture
So, how does Kappa architecture actually work? There are a few key components to consider:
Data Ingestion: Continuous streams of data flow from sources into a message broker, such as Apache Kafka. This broker acts as a durable storage system, provides data for real-time processing, and ensures that data is unified and immutable.
Stream Processing: Real-time engines, like Apache Flink, transform, enrich, and aggregate data streams to generate actions and insights.
Data Storage: Processed data is saved in various systems like data lakes, NoSQL databases, relational databases, or formats like Apache Iceberg, ensuring long-term storage, scalable access, and structured querying.
Replayability and Reprocessing: The architecture allows replaying historical data from storage when processing logic changes or errors need correction, ensuring adaptability to evolving requirements.
Scalability: Horizontal scaling enables efficient handling of large data volumes through distributed systems.
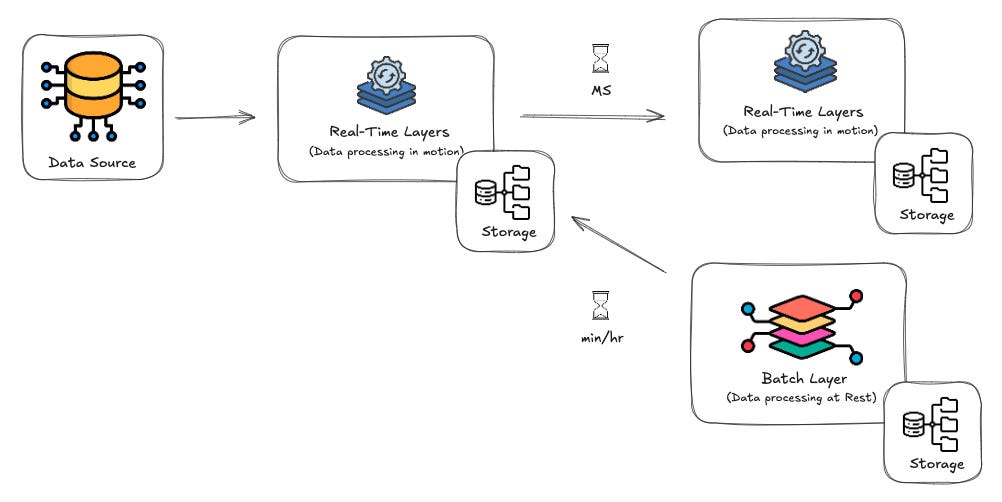
Advantages of Kappa Architecture
Simplicity: Kappa Architecture is easier to manage and maintain with a single processing layer than Lambda Architecture.
Real-Time Insights: By processing data as it arrives, businesses gain near-instant insights, enabling faster responses.
Adaptability: The ability to reprocess streams ensures that Kappa systems remain flexible to changing business needs.
Scalability: Distributed systems allow Kappa Architecture to scale efficiently with increasing data volumes.
Cost Efficiency: Eliminating the batch layer reduces resource requirements, saving costs on infrastructure and maintenance.
Kappa Architecture and Shifting Left
The concept of "Shift Left" originated in software development, emphasizing the idea of addressing potential problems early in the lifecycle—moving them "left" on the project timeline/architecture. In data processing and Kappa architecture, "Shift Left" means bringing data validation, transformation, and enrichment closer to the point of ingestion. This approach ensures data quality and reduces errors early in the processing pipeline, minimizing costly rework later.
Shift left has several benefits as we talked about last week.
Faster, More Efficient Processing – Data quality can be assured in flight, reducing errors and the need for costly reprocessing.
Real-Time Insights and Actions—Businesses can make immediate decisions based on live data instead of waiting for batch jobs.
Cost Savings – Compute resources are only used where needed, avoiding unnecessary processing of low-value data.
In Kappa Architecture, adopting a "Shift Left" approach complements its principles by enhancing real-time processing and reducing latency. These methodologies create a robust, efficient system for managing modern data workflows.
Kappa Architecture in Practice
Kappa Architecture is a modern design principle adopted by companies to build real-time data pipelines and analytics systems. Here are some key examples of companies successfully implementing Kappa Architecture:
Netflix leverages a unified streaming architecture to manage billions of events daily. With Apache Kafka and Apache Flink, Netflix’s system processes user activity, content recommendations, and operational analytics in real time, ensuring seamless customer experiences. Learn more about Netflix’s architecture.
A bunch of your favorite services are powered by Kappa architectures read more on them here: Uber, Shopify, LinkedIn, and Stripe
Conclusion
Kappa Architecture and a Shift-Left approach is the modern way to build real-time systems. Kappa Architecture produces many advantages over Lambda, including speed, simplicity, scalability, and competitive advantage.
Get in touch with us if you want to learn how Streamkap can simplify your journey to shift left architecture.
Warmly,
Paul Dudley
P.S. 🤫 If you’re in San Francisco and want to catch up with fellow data folks, join us on February 18 at 6 PM for a Low-Key Data Happy Hour meetup hosted by Tony Fancher and me. There will be no slides, no sales, just real conversations over drinks.
✅ Connect with data professionals
✅ Debate modern data stacks
✅ Share real-world challenges—without PowerPoint